The material below comprises excerpts from books by Dr. Johnathan Mun, our CEO and founder, such as Readings in Certified Quantitative Risk Management, 3rd Edition, and Quantitative Research Methods Using Risk Simulator and ROV BizStats Software Applying Econometrics, Multivariate Regression, Parametric and Nonparametric Hypothesis Testing, Monte Carlo Risk Simulation, Predictive Modeling, and Optimization, 4th Edition (https://www.amazon.com/author/johnathanmun). All screenshots and analytical models are run using the ROV Risk Simulator and ROV BizStats software applications. Statistical results shown are computed using Risk Simulator or BizStats. Online Training Videos are also available on these topics as well as the Certified in Quantitative Risk Management (CQRM) certification program. All materials are copyrighted as well as patent protected under international law, with all rights reserved.
Artificial Intelligence (AI) is a broad catch-all term for a group of inorganic computer science technologies that are used to simulate intelligence. The science of AI was established in the 1950s to determine whether inorganic robots could execute human-level intelligence capabilities. Significant interest in AI resurfaced about the same time as Big Data computer capacity became more widely available to researchers and businesses, allowing them to apply the science to a variety of practical applications. Manufacturing robots, smart assistants, proactive healthcare management, illness mapping, automated financial investing, virtual travel-booking agents, social media monitoring, conversational marketing bots, natural language processing tools, and inventory supply chain management are all examples of commercially feasible AI applications.
The timeline of AI and Data Science development reveals a long journey, where mathematical statistics evolved into applied statistics, data science, artificial intelligence, and machine learning (ML). For instance, in 1962, John Tukey’s work as a mathematical statistician can be considered one of the early seminal works in data analytics. In 1977, the International Association for Statistical Computing (IASC) was founded to link traditional statistical methodology, modern computer technology, and the knowledge of domain experts to convert data into information and knowledge. Database marketing started a trend in 1994, and by 1996, the term “Data Science” appeared for the first time at the International Federation of Classification Societies in Japan. The inaugural topic was entitled, “Data Science, Classification, and Related Methods.” In 1997, Jeff Wu gave an inaugural lecture titled simply “Statistics = Data Science?” In 2001, William Cleveland published “Data Science: An Action Plan for Expanding the Technical Areas of the Field of Statistics.” He put forward the notion that data science was an independent discipline and named various areas in which he believed data scientists should be educated: multidisciplinary investigations, models, and methods for data analysis; computing with data; pedagogy; tool evaluation; and theory. By 2008, the term “data scientist” was often attributed to Jeff Hammerbacher and D. J. Patil, then of Facebook and LinkedIn, respectively, and in 2010, the term “data science” had fully infiltrated the vernacular. Between 2011 and 2012, “data scientist” job listings increased by 15,000%. Around 2016, data science started to be entrenched in Machine Learning and Deep Learning. This implies that AI/ML techniques are based solidly on the foundations of traditional mathematical statistics, but with smart algorithmic steps wrapped around these methods.
The term AI typically conjures up the nebulous concept of machine learning, which, in reality, is a subset of AI where a computer system is programmed to identify and categorize external real-world stimuli. AI can be loosely defined as the ability of machines to perform tasks that normally require human intelligence—for example, recognizing patterns, learning from experience, drawing conclusions, making predictions, or taking action—whether digitally or as the smart software behind autonomous physical systems. AI processes that are most appropriate for data science, quantitative research analytics, prediction, and forecast modeling include applications of Machine Learning (ML), Natural Language Processing (NLP), and Robotic Process Automation (RPA).
Whereas AI, in general, involves the use of algorithms exhibiting “smart” behavior, the use of AI algorithms in Machine Learning (ML)—that detect patterns and use them for prediction and decision making—can be broadly divided into supervised and unsupervised methods. Supervised learning means that the correct answers are provided by humans to train the algorithm, whereas unsupervised learning does not include the correct results. Supervised algorithms are taught patterns using past data and then detect them automatically in new data. For example, a multiple regression model requires historical data of the dependent variable Y and one or more independent variables ![]() and because the results (dependent variable) are provided, this is considered a supervised ML algorithm. In contrast, unsupervised algorithms are programmed to detect new and interesting patterns in completely new data. Without supervision, the algorithm is not expected to surface specific correct answers; instead, it looks for logical patterns within raw data. For example, a factor analysis where there are multiple independent variables
and because the results (dependent variable) are provided, this is considered a supervised ML algorithm. In contrast, unsupervised algorithms are programmed to detect new and interesting patterns in completely new data. Without supervision, the algorithm is not expected to surface specific correct answers; instead, it looks for logical patterns within raw data. For example, a factor analysis where there are multiple independent variables ![]() but the a priori groupings of these variables are not known would be considered an unsupervised method. Reinforcement Learning is where the algorithm helps to make decisions on how to act in certain situations, and the behavior is rewarded or penalized depending on the consequences. Deep Learning is another class of ML inspired by the human brain where artificial neural networks progressively improve their ability to perform a task.
but the a priori groupings of these variables are not known would be considered an unsupervised method. Reinforcement Learning is where the algorithm helps to make decisions on how to act in certain situations, and the behavior is rewarded or penalized depending on the consequences. Deep Learning is another class of ML inspired by the human brain where artificial neural networks progressively improve their ability to perform a task.
NLP is a set of algorithms for interpreting, transforming, and generating human language in a way that people can understand. It is used in devices that appear to be able to understand and act on written or spoken words, such as translation apps or personal assistants like Apple Siri, Amazon’s Alexa, or Google Home. Speech soundwaves are converted into computer code that the algorithms understand. The code then translates that meaning into a human-readable, precise response that can be applied to normal human cognition. This is performed using semantic parsing, which maps a passage’s language to categorize each word and, using ML, creates associations to represent not just the definition of a term, but the meaning within a specific context.
Finally, while RPA, the algorithms that mimic human actions to reduce simple but repetitive back-office tasks benefits from AI application, RPA is not a simulation of human intelligence, but, rather, it only mimics capabilities. Strictly speaking, it is not AI; it is an existing process that has been augmented by AI. RPA can be loosely defined as the use of technology to set up computer software or robots to capture and interpret current applications for processing transactions, altering data, triggering reactions, and communicating with other digital systems. When used correctly, robotic automation offers numerous benefits because it is not constrained by human limitations such as weariness, morale, discipline, or survival requirements. Robots, unlike their human creators, have no ambitions. Due to the applications of NLP and RPA that are beyond the realm of decision analytics, data analytics, and quantitative research methods, we will only focus on ML applications in BizStats going forward.
Figure 9.54 provides a visualization of AI/ML methods. In the figure, AI/ML is divided into supervised learning and unsupervised learning. K-Nearest Neighbor can be considered the in-between method of semi-supervised in the sense that both training and testing sets are required, whereas strictly speaking, both supervised and unsupervised methods do not require a testing set. However, in practice, testing sets are typically used in order to apply the training set’s fitted parameters to the testing data points for forecasting or classification.
The following sections describe the AI/ML algorithms that are available in BizStats. Each method is first discussed, then an example is shown on how BizStats is applied, followed by results interpretation. Note that AI/ML methods rely heavily on standard statistics and analytical methods, and where appropriate, cross-referencing to other standard methods will be discussed.
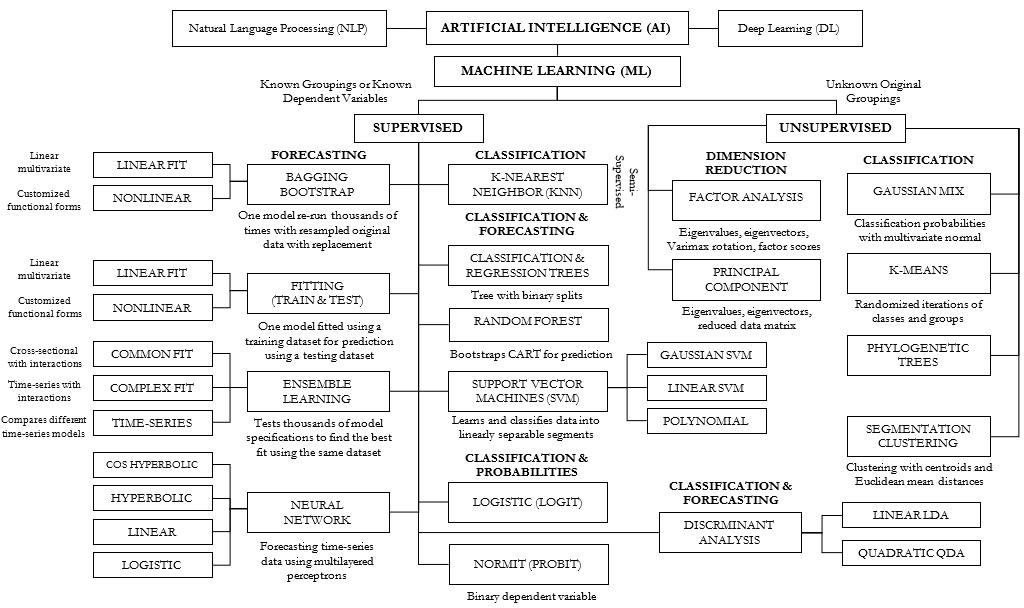
Figure 9.54: Artificial Intelligence Machine Learning Methods