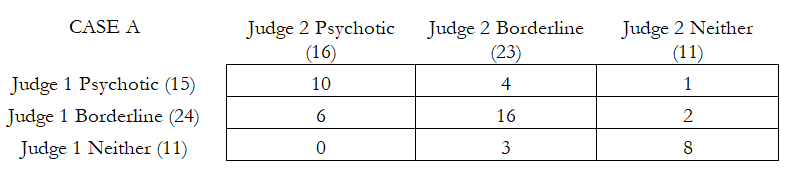
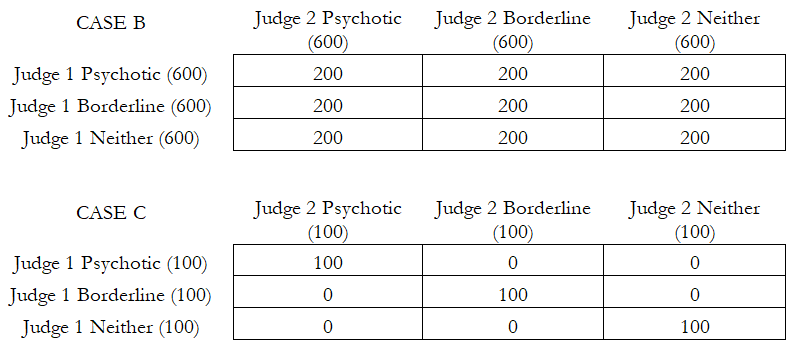
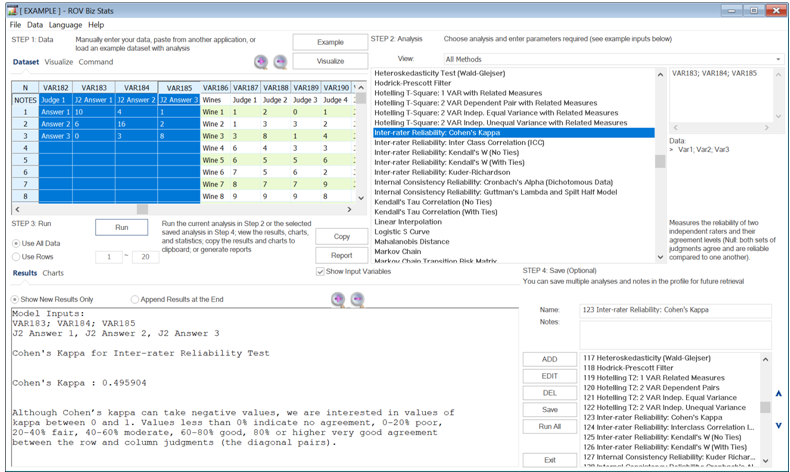
Cohen’s Kappa test can be applied to test for the reliability of two raters. The null hypothesis tested is that both sets of judgments agree and are consistent. In the following table, we see four example cases. In each situation, there are two judges or raters.
In Case A, there are 50 patients, and the first rater (physician or healthcare worker) judges 15 of them as being psychotic, 24 borderline, and 11 neither. In comparison, the second rater or judge finds 16, 23, and 11 patients within these respective categories. The patients that fall within the same judgment categories are shown in the grid. Both judges agree that 10 are psychotic, 16 are borderline, and 8 are neither, with a total of 34 findings in agreement out of 50 cases (this can be read off the diagonal in the data grid). The results from BizStats indicate that Cohen’s Kappa = 0.4959 or 49% agreement. In Case B, we see that the data grid is equally distributed with 200 patients in each block, and the computed Cohen’s Kappa = 0.0000, indicating absolutely no consistency and reliability between these two raters spread evenly. Case C, as you would imagine, returns Cohen’s Kappa = 1.0000. Finally, in Case D, where reliability is actually not just zero, but there is no value between the corresponding pairs, we obtain a Cohen’s Kappa = –0.50902. Clearly, a high positive Cohen’s Kappa measure is desirable for inter-rater reliability.