File Name: Analytics – Regression Diagnostics
Location: Modeling Toolkit | Analytics | Regression Diagnostics
Brief Description: Shows how to run a Diagnostic Analysis on your data before generating forecast models.
Requirements: Modeling Toolkit, Risk Simulator
Most forecast models (e.g., time-series, extrapolation, ARIMA, regression, and others) suffer from model errors because analysts neglect to check the data for the correct model assumptions (autocorrelation, heteroskedasticity, micronumerosity, multicollinearity, nonlinearity, outliers, seasonality, sphericity, stationarity, structural breaks, and others). This model provides a sample dataset on which we can run Risk Simulator’s Diagnostic tool in order to determine the econometric properties of the data. The diagnostics include checking the data for heteroskedasticity, nonlinearity, outliers, specification errors, micronumerosity, stationarity and stochastic properties, normality and sphericity of the errors, and multicollinearity. Each test is described in more detail in its respective report in the model.
Procedure
To run the analysis, follow the instructions below:
- Go to the Time-Series Data worksheet and select the data including the variable names (cells C5:H55).
- Click on Risk Simulator | Analytical Tools | Diagnostic Tool.
- Check the data and select the Dependent Variable Y from the drop-down menu. Click OK when finished (Figure 6.1).
Spend some time reading through the reports generated from this diagnostic tool.
A common violation in forecasting and regression analysis is heteroskedasticity, that is, the variance of the errors increases over time (see Figure 6.2 for test results using the Diagnostic tool). Visually, the width of the vertical data fluctuations increases or fans out over time, and the coefficient of determination (R-squared coefficient) typically drops significantly when heteroskedasticity exists. If the variance of the dependent variable is not constant, then the error’s variance will not be constant. Unless the heteroskedasticity of the dependent variable is pronounced, its effect will not be severe: The least-squares estimates will still be unbiased, and the estimates of the slope and intercept will be either normally distributed if the errors are normally distributed, or at least normally distributed asymptotically (as the number of data points becomes large) if the errors are not normally distributed. The estimate for the variance of the slope and overall variance will be inaccurate, but the inaccuracy is not likely to be substantial if the independent-variable values are symmetric about their mean.
![]()
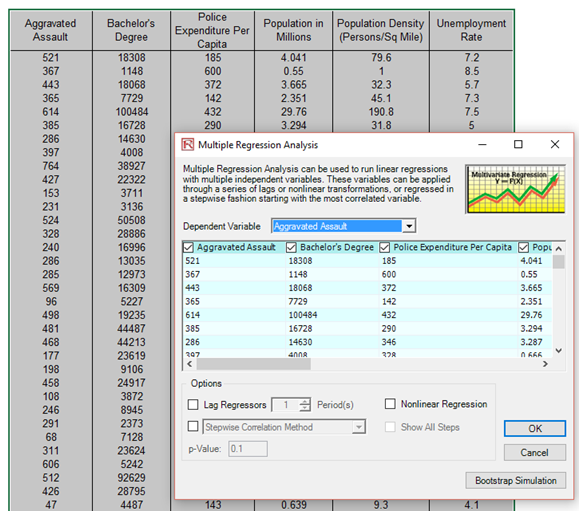
Figure 6.1: Running the data diagnostic tool
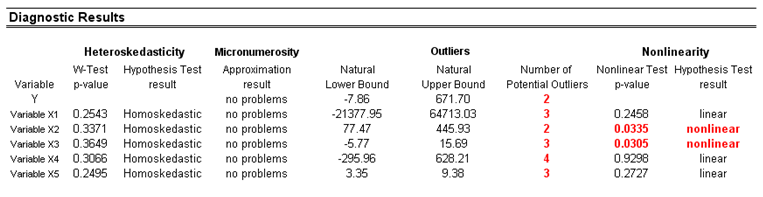
Figure 6.2: Results from tests of outliers, heteroskedasticity, micronumerosity, and nonlinearity
If the number of data points is small (micronumerosity), it may be difficult to detect assumption violations. With small sample sizes, assumption violations such as non-normality or heteroskedasticity of variances are difficult to detect even when they are present. With a small number of data points, linear regression offers less protection against the violation of assumptions. With few data points, it may be hard to determine how well the fitted line matches the data, or whether a nonlinear function would be more appropriate. Even if none of the test assumptions is violated, a linear regression on a small number of data points may not have sufficient power to detect a significant difference between the slope and zero, even if the slope is nonzero. The power depends on the residual error, the observed variation in the independent variable, the selected significance alpha level of the test, and the number of data points. Power decreases as the residual variance increases, decreases as the significance level is decreased (i.e., as the test is made more stringent), increases as the variation in observed independent variable increases, and increases as the number of data points increases.
Values may not be identically distributed because of the presence of outliers. Outliers are anomalous values in the data. They may have a strong influence over the fitted slope and intercept, giving a poor fit to the bulk of the data points. Outliers tend to increase the estimate of residual variance, lowering the chance of rejecting the null hypothesis, that is, creating higher prediction errors. They may be due to recording errors, which may be correctable, or they may be due to not all of the dependent-variable values being sampled from the same population. Apparent outliers may also be due to the dependent-variable values being from the same, but non-normal, population. However, a point may be an unusual value in either an independent or dependent variable without necessarily being an outlier in the scatter plot. In regression analysis, the fitted line can be highly sensitive to outliers. In other words, least squares regression is not resistant to outliers, thus, neither is the fitted-slope estimate. A point vertically removed from the other points can cause the fitted line to pass close to it, instead of following the general linear trend of the rest of the data, especially if the point is relatively far horizontally from the center of the data.
However, great care should be taken when deciding if the outliers should be removed. Although in most cases the regression results look better when outliers are removed, a priori justification must first exist. For instance, if one is regressing the performance of a particular firm’s stock returns, outliers caused by downturns in the stock market should be included; these are not truly outliers. Rather they are inevitabilities in the business cycle. Forgoing these outliers and using the regression equation to forecast one’s retirement fund based on the firm’s stocks will yield incorrect results at best. In contrast, suppose the outliers are caused by a single nonrecurring business condition (e.g., merger and acquisition) and such business structural changes are not forecast to recur. Then these outliers should be removed, and the data cleansed prior to running a regression analysis. The analysis here only identifies outliers; it is up to the user to determine if they should remain or be excluded.
Sometimes a nonlinear relationship between the dependent and independent variables is more appropriate than a linear relationship. In such cases, running a linear regression will not be optimal. If the linear model is not the correct form, then the slope and intercept estimates and the fitted values from the linear regression will be biased, and the fitted slope and intercept estimates will not be meaningful. Over a restricted range of independent or dependent variables, nonlinear models may be well approximated by linear models (this is, in fact, the basis of linear interpolation), but for accurate prediction, a model appropriate to the data should be selected. A nonlinear transformation should be applied to the data first before running a regression. One simple approach is to take the natural logarithm of the independent variable (other approaches include taking the square root or raising the independent variable to the second or third power) and run a regression or forecast using the nonlinearly transformed data.
Another typical issue when forecasting time-series data is whether the independent-variable values are truly independent of each other or whether they are dependent. Dependent-variable values collected over a time series may be autocorrelated. For serially correlated dependent-variable values, the estimates of the slope and intercept will be unbiased, but the estimates of their forecast and variances will not be reliable; hence the validity of certain statistical goodness-of-fit tests will be flawed. For instance, interest rates, inflation rates, sales, revenues, and many other time-series data typically are autocorrelated, where the value in the current period is related to the value in a previous period, and so forth (clearly, the inflation rate in March is related to February’s level, which, in turn, is related to January’s level, and so forth). Ignoring such blatant relationships will yield biased and less accurate forecasts. In such events, an autocorrelated regression model or an ARIMA model may be better suited (Risk Simulator | Forecasting | ARIMA). Finally, the autocorrelation functions of a series that is nonstationary tend to decay slowly (see the Nonstationary report in the model).
If autocorrelation AC(1) is nonzero, it means that the series is first-order serially correlated. If AC(k) dies off more or less geometrically with increasing lag, it implies that the series follows a low-order autoregressive process. If AC(k) drops to zero after a small number of lags, it implies that the series follows a low-order moving-average process. Partial correlation PAC(k) measures the correlation of values that are k periods apart after removing the correlation from the intervening lags. If the pattern of autocorrelation can be captured by an autoregression of order less than k, then the partial autocorrelation at lag k will be close to zero. Ljung-Box Q-statistics and their p–values at lag k have the null hypothesis that there is no autocorrelation up to order k. The dotted lines in the plots of the autocorrelations are the approximate two standard error bounds. If the autocorrelation is within these bounds, it is not significantly different from zero at the 5% significance level.
Autocorrelation measures the relationship to the past of the dependent Y variable to itself. Distributive lags, in contrast, are time-lag relationships between the dependent Y variable and different independent X variables. For instance, the movement and direction of mortgage rates tend to follow the Federal Funds Rate but at a time lag (typically 1 to 3 months). Sometimes, time lags follow cycles and seasonality (e.g., ice cream sales tend to peak during the summer months and hence are related to last summer’s sales, 12 months in the past). The distributive lag analysis (Figure 6.3) shows how the dependent variable is related to each of the independent variables at various time lags, when all lags are considered simultaneously, to determine which time lags are statistically significant and should be considered.
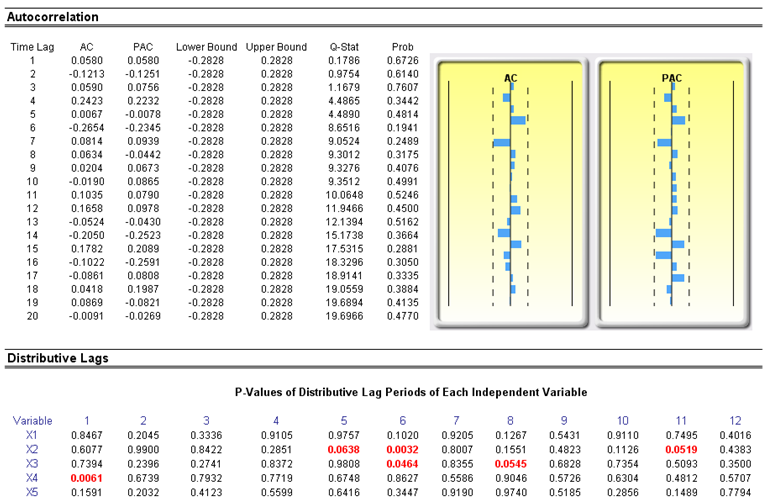
Figure 6.3: Autocorrelation and distributive lag results
Another requirement in running a regression model is the assumption of normality and sphericity of the error term. If the assumption of normality is violated or if outliers are present, then the linear regression goodness-of-fit test may not be the most powerful or informative test available, and this could mean the difference between detecting a linear fit or not. If the errors are not independent and not normally distributed, it may indicate that the data might be autocorrelated or suffer from nonlinearities or other more destructive errors. Independence of the errors can also be detected in the heteroskedasticity tests (Figure 6.4).
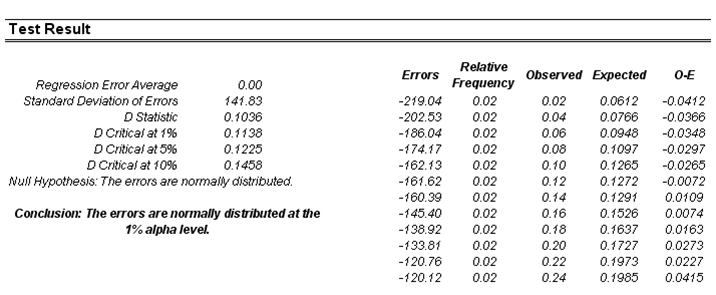
Figure 6.4: Test for normality of errors
The Normality test performed on the errors is a nonparametric test, which makes no assumptions about the specific shape of the population from which the sample is drawn, thus allowing for smaller sample datasets to be analyzed. This test evaluates the null hypothesis of whether the sample errors were drawn from a normally distributed population, versus an alternate hypothesis that the data sample is not normally distributed. If the calculated D-Statistic is greater than or equal to the D-Critical values at various significance values, then reject the null hypothesis and accept the alternate hypothesis (the errors are not normally distributed). Otherwise, if the D-Statistic is less than the D-Critical value, do not reject the null hypothesis (the errors are normally distributed). This test relies on two cumulative frequencies: one derived from the sample dataset and the second, from a theoretical distribution based on the mean and standard deviation of the sample data.
Sometimes, certain types of time-series data cannot be modeled using any other methods except for a stochastic process, because the underlying events are stochastic in nature. For instance, you cannot adequately model and forecast stock prices, interest rates, price of oil, and other commodity prices using a simple regression model because these variables are highly uncertain and volatile, and do not follow a predefined static rule of behavior; in other words, the process is not stationary. Stationarity is checked here using the Runs Test while another visual clue is found in the Autocorrelation report (the ACF or autocorrelation function tends to decay slowly). A stochastic process is a sequence of events or paths generated by probabilistic laws. That is, random events can occur over time but are governed by specific statistical and probabilistic rules. The main stochastic processes include Random Walk or Brownian Motion, Mean-Reversion, and Jump-Diffusion. These processes can be used to forecast a multitude of variables that seemingly follow random trends but are restricted by probabilistic laws. The process-generating equation is known in advance but the actual results generated are unknown (Figure 6.5).
The Random Walk Brownian Motion process can be used to forecast stock prices, prices of commodities, and other stochastic time-series data given a drift or growth rate and volatility around the drift path. The Mean-Reversion process can be used to reduce the fluctuations of the Random Walk process by allowing the path to target a long-term value, making it useful for forecasting time-series variables that have a long-term rate such as interest rates and inflation rates (these are long-term target rates by regulatory authorities or the market). The Jump-Diffusion process is useful for forecasting time-series data when the variable occasionally can exhibit random jumps, such as oil prices or the price of electricity (discrete exogenous event shocks can make prices jump up or down). These processes also can be mixed and matched as required.
Multicollinearity exists when there is a linear relationship between the independent variables. When this occurs, the regression equation cannot be estimated at all. In near collinearity situations, the estimated regression equation will be biased and provide inaccurate results. This situation is especially true when a step-wise regression approach is used, where the statistically significant independent variables will be thrown out of the regression mix earlier than expected, resulting in a regression equation that is neither efficient nor accurate. One quick test of the presence of multicollinearity in a multiple regression equation is that the R-squared value is relatively high while the t-statistics are relatively low.
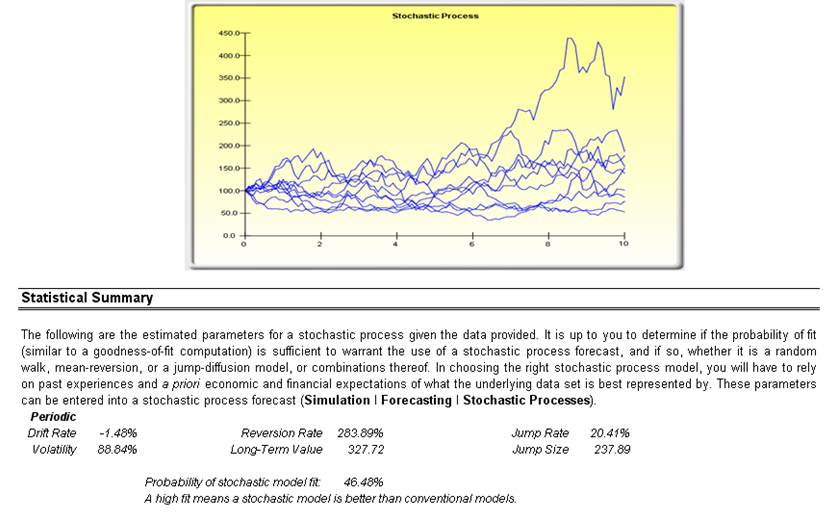

Figure 6.5: Stochastic process parameter estimation
Another quick test is to create a correlation matrix between the independent variables. A high cross-correlation indicates a potential for autocorrelation. The rule of thumb is that a correlation with an absolute value greater than 0.75 is indicative of severe multicollinearity. Another test for multicollinearity is the use of the Variance Inflation Factor (VIF), obtained by regressing each independent variable to all the other independent variables, obtaining the R-squared value, and calculating the VIF. A VIF exceeding 2.0 can be considered as severe multicollinearity. A VIF exceeding 10.0 indicates destructive multicollinearity (Figure 6.6).
The Correlation Matrix lists the Pearson’s Product Moment Correlations (commonly referred to as the Pearson’s R) between variable pairs. The correlation coefficient ranges between –1.0 and +1.0 inclusive. The sign indicates the direction of association between the variables, while the coefficient indicates the magnitude or strength of association. The Pearson’s R only measures a linear relationship and is less effective in measuring nonlinear relationships.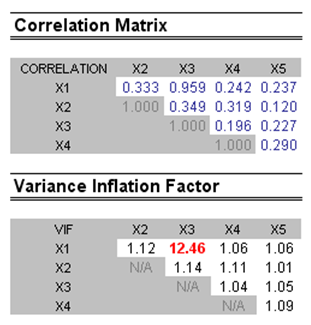
Figure 6.6: Multicollinearity errors
To test whether the correlations are significant, a two-tailed hypothesis test is performed and the resulting p–values are computed. P–values less than 0.10, 0.05, and 0.01 are highlighted in blue to indicate statistical significance. In other words, a p–value for a correlation pair that is less than a given significance value is statistically significantly different from zero, indicating that there is significant a linear relationship between the two variables.
The Pearson’s Product Moment Correlation Coefficient (R) between two variables (x and y) is related to the covariance (cov) measure where
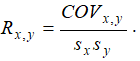
The benefit of dividing the covariance by the product of the two variables’ standard deviations (s) is that the resulting correlation coefficient is bounded between –1.0 and +1.0 inclusive. This makes the correlation a good relative measure to compare among different variables (particularly with different units and magnitude). The Spearman rank-based nonparametric correlation is also included. The Spearman’s R is related to the Pearson’s R in that the data are first ranked and then correlated. Rank correlations provide a better estimate of the relationship between two variables when one or both of them is nonlinear.
It must be stressed that a significant correlation does not imply causation. Associations between variables in no way imply that the change of one variable causes another variable to change. Two variables that are moving independently of each other but in a related path may be correlated, but their relationship might be spurious (e.g., a correlation between sunspots and the stock market might be strong, but one can surmise that there is no causality and that this relationship is purely spurious).