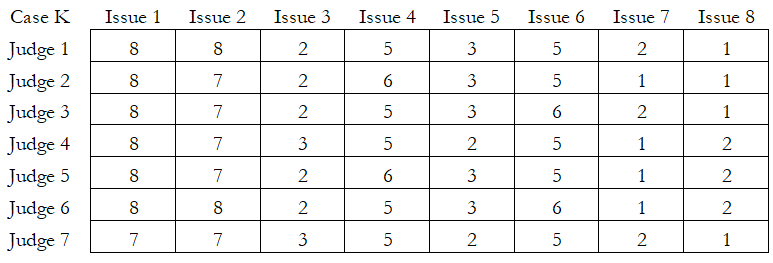
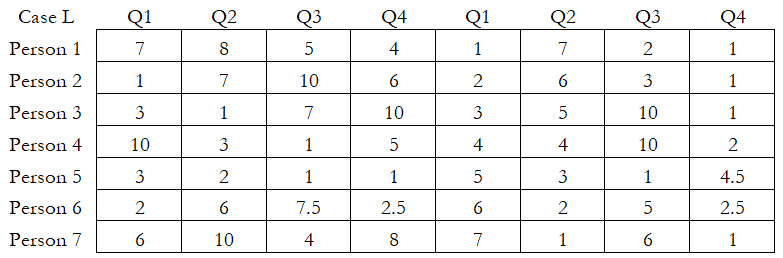
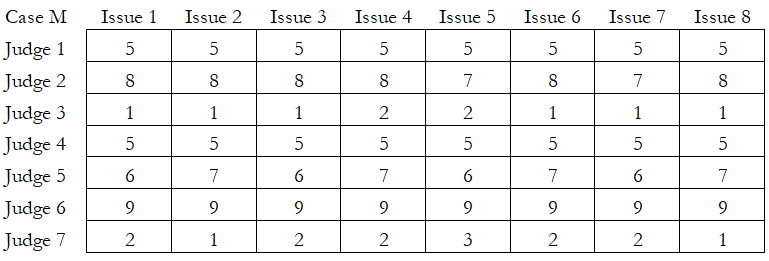
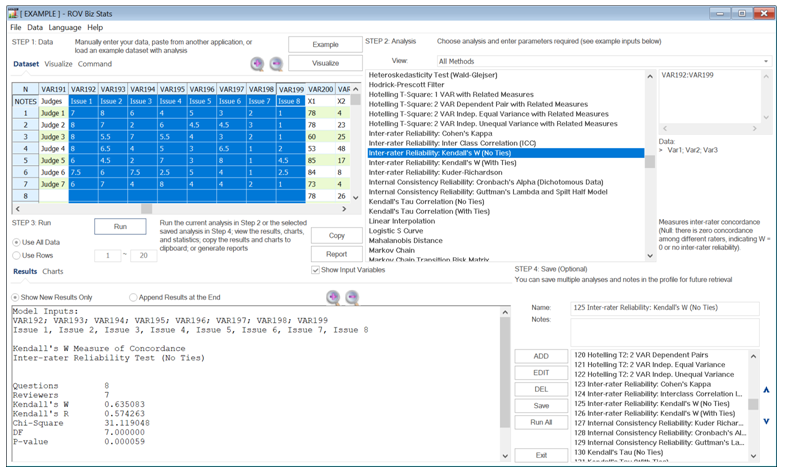
Another test for the inter-rater reliability is the Kendall’s W measure, which can be run with ties or without ties. A tie means there are multiple data points with the same value, and, hence, we must split the difference between these ties. Regardless, the null hypothesis for these tests is that there is zero agreement (W = 0) among all the judges.
Case K in the table below returns a calculated Kendall’s W = 1.1068, Kendall’s R = 1.124646, and p-value = 0.0000. We reject the null hypothesis and conclude that there is agreement among the judges. For instance, we see that Issue 1 is critical for all judges, whereas Issues 3, 7, and 8 are rated lower. All ratings are consistent among all the judges.
In Case L, Kendall’s W = 0.2261, Kendall’s R = 0.0971, and p-value = 0.1352. This indicates that we cannot reject the null hypothesis and conclude that there is no statistical concordance among the different respondents answering the survey questions.
Finally, in Case M, Kendall’s W = 0.0028, Kendall’s R = -0.1633, and p-value = 0.9999. This certainly indicates extremely low consistency and reliability among the respondents.