- Related AI/ML Methods: Regression Trees CART,
- Related Traditional Methods: Bootstrap Simulation, Bootstrap Regression
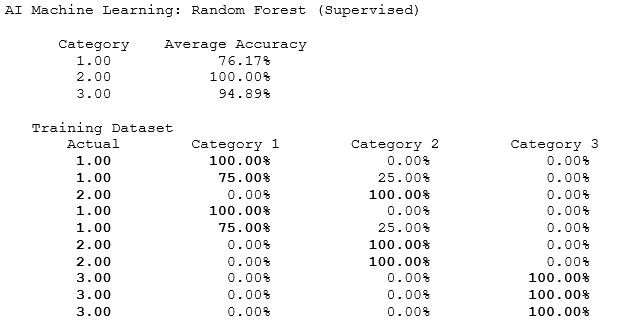
In this approach, bootstraps of regression trees are run multiple times with different combinations of data points and variables to develop a consensus forecast of group assignments. Using a single set of Training Y and Training X variables, the data and variables are bootstrapped and resampled. Each resampling will be run in the CART or classification and regression tree model, and the consensus categorization results will be generated (Figure 9.80). The benefit of random forests is that it provides a consensus forecast (wisdom of the crowd) through a resampling with replacement of both the variables and the data points. However, the individual CART model and tree process will no longer be available. To get started with this approach, enter the variables you need to classify and enter the number of clusters desired. The required model inputs look like this:

Figure 9.80: AI/ML Random Forest
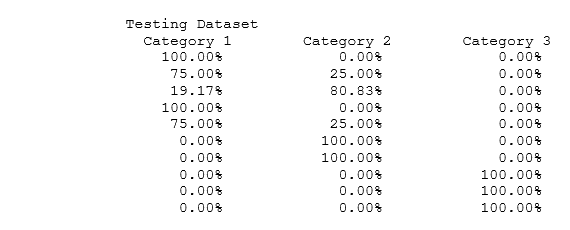
Suppose we apply the entire dataset and bootstrapped it (i.e., minimum variables is 4 and the minimum data points to use is 10, which means the entire dataset is utilized), the results will be identical to the AI/ML Classification and Regression Tree CART model. Recall that the CART results had 100% for all three categories. In this random forest model, if we only apply a minimum of 3 variables with 9 data rows, we see the results shown next. Hundreds of CART models are bootstrapped, and the averages of the results are obtained. The testing dataset’s categorization shows that the highest probability events are in categories 1, 1, 2, 1, 1, 2, 2, 3, 3, 3, which also corresponds to the single CART model results. All other results follow the same interpretation as the CART model.